
隨著人工智慧(AI)技術的快速進步,AI 影像辨識(Computer Vision)已經不再只是科幻故事中的情節,而是廣泛應用於日常生活及產業中。從智慧手機的臉部解鎖、監視器的異常偵測,到醫療影像分析及智慧製造瑕疵檢測,影像辨識技術為各行各業帶來革命性的轉變。本篇文章將深入介紹 AI 影像辨識的核心概念與技術原理,探討不同模型的運作方式與適用情境,並分析各行業應用、導入挑戰與未來趨勢。文章最後會提供戰國策 AI 企業解決方案,協助企業落實數位轉型。
AI 影像辨識是什麼?核心模型有哪些?
AI 影像辨識是利用人工智慧讓電腦「看」懂照片或影片中的內容。傳統的影像處理多是針對圖像做演算法運算,例如邊緣檢測、色彩調整等,但並不理解圖像代表的意義。AI 影像辨識則透過機器學習模型,將圖像轉成向量,再從大量的訓練資料中學會如何區分不同的物體或事件。
模型1:卷積神經網路(CNN)— 從小細節一路看到整體
卷積神經網路(Convolutional Neural Network,CNN)是影像辨識最常見的架構,你可以把 CNN 想像成一個會學習的視覺系統,是一種專門用來分析圖片的深度學習模型,它不會一次看整張圖,而是把圖片切成許多小區域,先從線條、邊緣、顏色變化等簡單特徵開始學習,再一層層堆疊,逐漸看出完整的形狀與物體,讓模型能有效抓出圖片中的重要資訊。
CNN 的卷積核會像「特徵偵測器」一樣在整張圖片上移動,同一組偵測器可以在不同位置找到相同特徵,讓模型的參數更少、訓練更快。每個偵測到的結果會形成「特徵圖」,代表圖片中出現哪些形狀或紋理;之後再透過池化(Pooling)縮小資料、保留重點,使運算更有效率。經過多層特徵萃取後,CNN 最後會將濃縮後的資訊進行分類,用來判斷影像屬於哪一類,例如辨識這是一隻貓、狗或汽車。由於會自己找重要特徵、你不需要手寫規則而且越訓練越聰明,使 CNN 成為影像辨識最常用、準確度最高的深度學習方法之一。
模型2:單一模型即時物件偵測(YOLO)— 能偵測物體位置的演算法
物件偵測比影像分類更困難,因為除了知道圖片裡有什麼,還要標出「它在哪裡」。傳統做法會先用區域候選方法找出可能的物體位置,再逐一分類,流程複雜、速度慢。而 YOLO(You Only Look Once)改變了這種做法,它把整個物件偵測的流程合併成一次運算。
YOLO 的方式是把圖片分成 S×S 的網格,每個網格負責預測落在該區域的物體,並直接輸出物體的位置與分類結果。因為不需要像傳統方法一樣反覆偵測與分類,YOLO 的處理速度非常快,適合即時應用,例如車牌辨識、行車監控、工廠生產線偵測等。自 2015 年由 Joseph Redmon 等人提出後,YOLO 系列持續更新,不斷提升準確度與速度,成為最常見的即時物件偵測演算法之一。
模型3:Vision Transformer(ViT)— 用讀語句的方式來理解整張圖片
Vision Transformer(ViT)是一種近年快速走紅的影像模型,它將原本用於自然語言處理的 Transformer 架構直接搬到電腦視覺中。它的思維與 CNN 完全不同,不再從小範圍的局部特徵開始累積,而是先把圖片切成一塊一塊的小方格(patch),把每一塊都當成「一句話中的一個字」,再把這些區塊組成一個序列輸入模型。每個區塊會被轉成向量,並加入表示原本位置的編碼,接著送入 Transformer,由自注意力機制同時觀察所有區塊,分析它們之間的關係。這種方式不用卷積運算,就可以一次看到整張圖片的全局關聯,因此特別擅長理解長距離的影像特徵。
由於能同時掌握整體結構與細節,Vision Transformer 在許多視覺任務上已經展現超越 CNN 的表現,包括影像分類、物體偵測與語義分割等。在 Google 於 2021 年提出的論文《An Image is Worth 16×16 Words》中,ViT 在大型資料集上展現極高準確度,也因為模型架構簡潔、擴充性高,很快成為電腦視覺領域的新主流。對許多需要全局理解的任務來說,ViT 提供了一種比傳統 CNN 更直接、更彈性的解決方案。
| 模型 | 核心技術 | 優點 | 缺點 | 適用情境 |
|---|---|---|---|---|
| CNN | 卷積、池化、權重共享 | 善於提取局部特徵,訓練速度快,已有成熟架構 | 缺乏全局視野,輸入大小固定 | 影像分類、簡單目標檢測 |
| YOLO | 單網路回歸邊界框,網格劃分 | 即時偵測、多物件處理、較少計算量 | 小物件易漏報,對錨點設置敏感 | 監控、智慧城市、自駕車 |
| Vision Transformer | 將影像切成 Patch,以自注意力建模關係 | 擁有全局視野、預訓練效果好、兼具分類與偵測 | 需要大量資料訓練,計算成本高 | 高準確率需求、語義分割、多模態任務 |
企業使用 AI 還有哪些優勢?你可以思考這 4 個問題 …
AI 影像辨識的 5 大運作流程
影像辨識系統的運作大致可分為以下步驟:
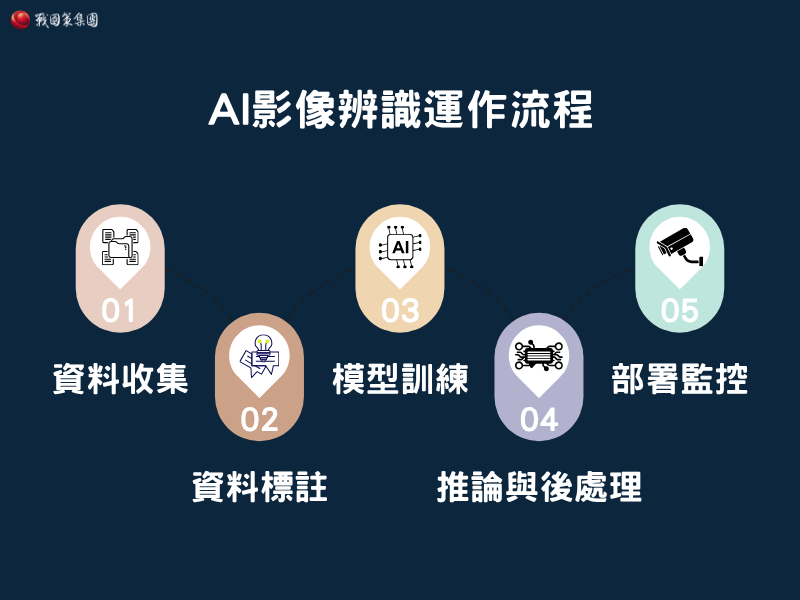
步驟1:資料收集
透過相機、醫療掃描儀或監控系統蒐集圖片或影片,資料量越大越能涵蓋各種情境。
步驟2:資料標註
透過人工或半自動方式為影像標記類別、邊界框或語義分割區域,建立訓練用的真實標籤。
步驟3:模型訓練
選擇適當的模型(CNN、YOLO、ViT 等)並輸入標註資料進行訓練,調整參數以最小化預測誤差。
步驟4:推論與後處理
將新影像輸入訓練好的模型,取得分類或偵測結果,並可加入後處理(例如非極大值抑制)提升精確度。
步驟5:部署與監控
將模型部署在雲端、邊緣裝置或現場設備中,持續監測其效能並更新資料,確保模型長期保持準確。
AI 影像辨識的應用案例
AI 影像辨識幾乎可以應用在所有需要「看」的場景。以下選取幾個具代表性的行業並做說明。
醫療影像分析
醫療影像包含 X 光、斷層掃描 (CT)、核磁共振 (MRI) 等,診斷過程複雜且需要專業醫師判讀。透過影像辨識技術,系統可以協助醫生在大量影像中標註出可疑區域,加速病灶篩選。例如在乳癌檢測中,AI 系統可以協助辨別腫瘤類型並提供置信度,降低漏診率。醫生與研究人員利用電腦視覺算法區分正常與癌變組織,能夠加速分析並確保記錄準確。更重要的是,AI 也能監控手術流程,追蹤手術器械位置,減少術中失誤。
更多 AI 醫療產業的發展趨勢可以參考這篇文章
智慧製造與瑕疵檢測
在製造業,影像辨識可用於檢測產品瑕疵、監控產線設備或計算產能。透過高速相機拍攝產品,再以 AI 模型分析是否有划痕、破損或尺寸不合,即時篩除不良品。智慧工廠還可以利用邊緣裝置就近處理影像,減少延遲並降低大量影像傳輸至雲端的成本。YOLO 與 ViT 等輕量模型能在低功耗裝置上執行,有利於產線即時反應。
智慧城市監控與交通分析
城市安全與交通管理是影像辨識的重要應用。監控系統結合 AI 可以自動偵測異常行為、闖紅燈、違規停車等情況,提高警力效率。在交通領域,影像辨識可用於車流量統計、車牌辨識和即時交通號誌控制,改善道路通行。台灣部分縣市已導入車牌 AI 辨識系統,結合 IoT 感測器打造智慧停車場,讓管理者及民眾更方便。
透過雲端運算、邊緣裝置與AI 分析技術的整合,戰國策物聯網應用(IOT)也讓企業能即時掌握營運數據、優化生產流程,並實現預測性維護與智慧決策。
零售與安全管理
零售店可以透過影像辨識分析顧客行為,例如停留熱區、購物路徑或年齡層,來調整商品陳列與行銷策略。大型購物中心利用人臉辨識提高會員服務效率,也能即時偵測可疑行為以降低損失。隨著隱私法規的嚴格,如何在分析消費行為的同時保護個人資訊將是重要課題。
| 行業 | 應用範例 | 效益 |
|---|---|---|
| 醫療 | AI 協助標註腫瘤、分割器官、預測病理結果 | 減少醫師負擔、提升診斷準確率 |
| 製造 | 瑕疵檢測、設備監控、產線優化 | 即時剔除不良品、降低成本 |
| 智慧城市 | 異常行為偵測、交通流量分析、車牌辨識 | 提升公共安全、改善交通效率 |
| 零售 | 顧客行為分析、人臉識別會員管理 | 精準行銷、強化安全 |
更多例子看懂什麼是AI應用 …
導入 AI 影像辨識系統的挑戰

大量資料與標註成本
AI 模型的成功高度依賴資料品質。要訓練一個表現良好的影像辨識模型,需要包含不同光線、角度及背景的多樣化圖像。收集與標註大量資料既耗時又昂貴,企業通常需要投入大量人力,或第三方專家如戰國策AI人工智慧顧問服務協助。此外,隨著模型持續運行,還需要不斷更新資料集來避免模型衰退。
個資保護與隱私問題
影像數據往往包含個人隱私,例如臉部特徵、車牌號碼等。AI 系統需要大量包含個人或敏感資訊的資料才能有效運作。然而,消費者對於企業使用 AI 處理個資普遍缺乏信任。因此,在開發影像辨識應用時,必須遵循法規(如 GDPR、個資法),採取匿名化、加密或邊緣運算等技術,減少對原始資料的傳輸與儲存。
演算法偏見與公平性
AI 技術可能繼承人類的偏見,例如依賴有誤的訓練資料或模型設計不當。某些臉部識別系統對深色皮膚女性的誤判率高達 35%,這些錯誤不僅影響個人權益,也會損害企業品牌。要減少偏見,可以採取資料多樣化、偏差測試、模型解釋及公平性評估等措施。
準確率與即時性的取捨
影像辨識應用往往需要在準確率與運算速度之間取得平衡。例如醫療影像強調精準度,而監控或自駕車則要求即時反應。邊緣運算被視為解決延遲問題的重要方案。將影像資料直接在智慧手機、無人機或 IoT 感測器上處理,可以減少傳輸延遲並實現即時視覺分析。然而,邊緣裝置算力有限,因此需要開發輕量模型(如 YOLO 或移除部分 CNN 結構)以降低運算負擔。
影響 AI 影像辨識未來發展的兩大關鍵
多模態 AI 的崛起
傳統 AI 模型通常只處理單一模態的資料(例如圖像或文字),但多模態深度學習使模型能同時理解不同類型的訊息。例如文字轉語音、影像轉影片,甚至結合圖像與文字作為統一的資訊來源。在醫療領域,結合醫師筆記與影像資料可提高診斷準確率。未來,結合語音、感測器數據與影像的多模態系統將在智慧城市、數位助理與穿戴裝置中發揮關鍵作用。
邊緣運算與輕量化模型
隨著 IoT 與智慧終端設備普及,將 AI 部署到邊緣裝置成為趨勢。
處理影像資料時,直接在捕捉資料的邊緣設備(如手機、無人機、監視器)上分析可減少延遲並實現即時反饋。然而,這些裝置資源有限,因此需要開發輕量化模型。例如傳統的 R‑CNN 雖然準確但計算成本高,而 YOLO 或 SSD 模型在不犧牲太多準確度的情況下能降低資源消耗。未來的影像辨識系統將結合邊緣與雲端,根據任務需求動態切換運算位置,以兼顧效能、隱私與成本。
常見問答(FAQ)
AI 影像辨識與傳統影像處理有什麼不同?
傳統影像處理透過固定演算法處理像素,無法理解圖像內容;AI 影像辨識利用機器學習模型從大量標註資料中學習特徵,能判斷圖像中的物件與事件,並在新情境下做出推論。
小型企業也能導入影像辨識系統嗎?
可以。近年來模型輕量化與邊緣運算技術成熟,企業可利用雲端 API 或嵌入式裝置以較低成本部署影像辨識。選擇適當的硬體與模型即可在監控、產品檢測或客戶分析上獲得效益。
影像辨識是否會侵犯個人資料?
影像資料確實可能包含個人資訊,因此需遵循相關法規。建議在系統設計時採取資料匿名化、加密與最小必要收集原則,並告知使用者資料用途。此外,可利用邊緣運算讓資料在本地處理,減少傳輸風險。
AI 影像辨識的準確率能達到多少?
準確率取決於資料品質、模型選擇與場景複雜度。在受控環境下,CNN 或 ViT 可達到九成以上的準確率,但在光線變化大、遮擋多或資料不足的情況下,準確率會下降。可透過資料擴增與模型微調提升表現。
台灣有哪些影像辨識應用案例?
台灣在智慧製造、智慧城市與醫療領域已有許多成功案例,例如以 AI 檢測產線瑕疵、利用車牌辨識管理智慧停車場,以及協助醫師判讀醫療影像等。政府與企業也逐漸採用邊緣運算裝置,提高系統即時性。
YOLO 和 SSD 有何差異?
YOLO 與 SSD(Single Shot Detector)皆屬於單階段目標偵測模型。YOLO 將整張圖像分為網格進行預測,速度快但對小物件偵測較弱;SSD 在不同尺度的特徵圖上做預測,對小物體表現較好,但計算量稍高。
Vision Transformer 是否會取代 CNN?
Vision Transformer 在大規模資料下表現優於 CNN,但其計算成本高且訓練資料需求大。未來可能會看到二者結合的混合架構,例如用 CNN 提取局部特徵、用自注意力捕捉全局關係,彼此取長補短。
如何避免模型偏見?
應該建立多元且平衡的資料集,並在開發流程中導入公平性評估。可利用專門的偏差測試工具檢視模型在不同族群上的表現,並通過資料重採樣或模型調整減少偏差。
邊緣運算會取代雲端服務嗎?
邊緣與雲端各有優勢。邊緣運算適合對延遲要求高或需要保護隱私的應用,雲端則提供強大計算資源與彈性。未來趨勢是將二者結合,根據任務特性分配運算負載。
導入影像辨識需要什麼硬體設備?
需求因應用而異。基本設備包括高解析度相機與運算平台;若需要即時偵測,可選擇具 GPU 或 AI 加速器的邊緣裝置。對於大規模訓練,則通常使用雲端伺服器或 GPU 叢集。
AI 影像辨識技術正在迅速改變世界
AI 影像辨識技術讓機器具備「看」的能力,幫助我們更快速、更準確地做出決策。如果您希望在企業導入專業的影像辨識系統、客製化 AI 應用或改善生產流程,歡迎了解 戰國策 AI 企業解決方案。戰國策擁有豐富的智慧視覺開發經驗,協助醫療、製造、零售與公共部門建立專屬的 AI 應用,能幫助您的企業順利完成數位轉型。
AI課程 >
生成式AI介紹 >
企業工作流程自動化(RPA)+AI >
AI顧問服務 >
AI塔羅決策輔助系統 >
企業專屬AI系統 >
企業常用AI指令 >
AI應用軟體系統開發服務>
戰國策 AI客服系統>
想了解更多,歡迎撥打服務專線 0800-003-191或加入戰國策官方LINE:@119m 免費諮詢。



