

- 20 6 月, 2025
- AI 專欄
AI 機器學習中有一些專有術語,如 NLP、強化學習、資料集等,卻不太清楚它們的用途與差別?本篇文章將帶你用簡單易懂的方式,一次搞懂這三大核心觀念,無論你是剛入門還是想補強基礎,都能快速建立清晰概念,讓你學 AI 不再霧煞煞。
AI機器學習|NLP 自然語言是什麼?
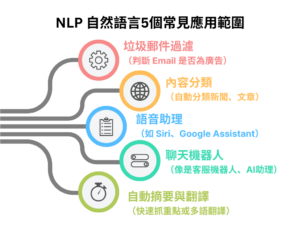
AI 機器學習的實際應用裡,NLP(自然語言處理)絕對是最常被提起的一個領域。從語音助理、客服機器人、文章推薦,到我們每天看的新聞分類、Email 垃圾信過濾,這些其實都靠 NLP 技術在運作。簡單來說,NLP 就是讓電腦能夠「聽懂人話、看懂文字」的 AI 技術,是 AI 與人類互動的一大突破。以下就帶你一步步了解什麼是 NLP,它到底怎麼運作、有哪些應用,以及為何它會成為 AI機器學習的核心技術之一。
NLP 是什麼?淺談 AI機器學習中的語言理解技術
NLP,全名是 Natural Language Processing,中文叫「自然語言處理」,是 AI機器學習的一個分支。它的目標,是讓電腦能理解、分析,甚至「產出」人類自然語言。
這不只限於聽說,還包括文字閱讀與回應,例如 Google 搜尋的自動建議、Siri 回答問題、ChatGPT 回你訊息,背後都靠 NLP 技術在運行。這些技術結合了語法分析、語意理解、語境判斷與機器學習模型,讓電腦可以模仿我們的語言邏輯。
NLP 應用案例有哪些?從垃圾郵件過濾到新聞分類
你可能沒發現,其實 NLP 已經悄悄融入我們的生活中。最常見的例子像是垃圾郵件過濾系統,它會自動判斷一封信是否為廣告信、釣魚信或真正重要的訊息,這背後就是透過文字分類模型。
另一個例子是新聞推薦或內容分類,AI 會依據文章內容幫你分類出哪些是政治新聞、娛樂話題,甚至能偵測出你常看的主題,自動幫你推播感興趣的內容。這些 NLP 應用都仰賴資料訓練與機器學習演算法的支撐。
為什麼 NLP 是 AI機器學習不可或缺的核心能力?
隨著人與科技互動越來越密切,NLP 不再只是「附加功能」,而是讓 AI 真正走進人類世界的關鍵。AI 若無法理解語言,就很難協助我們解決問題、提供建議或互動服務。
因此,NLP 不僅是語言工具,更是 AI 的「溝通橋樑」。尤其在客服、自動化回覆、語音識別、醫療紀錄分析、法律文書分類等產業中,NLP 技術已是不可或缺的一環。對於想學 AI 的人來說,掌握 NLP 的基礎觀念是邁入實戰的第一步。
更多AI機器學習知識請看:人工智慧 (AI) 與機器學習 (ML) 的不同之處
AI機器學習|強化學習中的「試錯學習法」
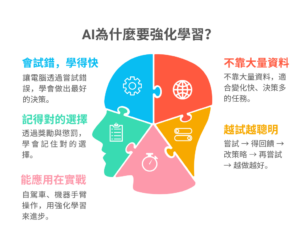
在 AI機器學習的領域中,「強化學習(Reinforcement Learning, RL)」是一種非常獨特的學習方式,它不像傳統模型依賴大量資料進行分析,而是透過「玩遊戲、做嘗試」來學習。你可以想像電腦是一個學習中的玩家,它每做一個動作就會獲得一個回饋,可能是獎勵、也可能是懲罰,電腦就這樣不斷「試錯」,直到找出最有利的策略。
強化學習與傳統 AI機器學習方式有什麼不同?
一般的 AI 機器學習,例如監督式學習(supervised learning),是透過「標示好的資料」來訓練模型,例如:「這張圖片是貓」或「這封信是垃圾信」,電腦學的是已知的答案;但強化學習則完全不同,它是在沒有明確答案的情況下,由系統自己去嘗試各種行動,根據結果收到的回饋來修正策略。
簡單來說,傳統學習像是在背書考試,而強化學習更像是電腦在「玩一場遊戲」,邊玩邊學,越來越厲害。
獎勵機制怎麼幫助 AI 找出最佳解?
強化學習最核心的概念就是「獎勵機制」,每當 AI 做出一個決策,就會得到一個回饋值(reward),好的決策給高分,錯的選擇可能沒分甚至扣分。電腦透過不斷嘗試不同動作,學會哪些選擇會帶來最大長期獎勵,這就好像是 AI 自己摸索出一套「生存法則」。
舉個例子,當 AI 控制角色闖關遊戲,它會學習「避開陷阱、收集寶物、快速過關」這些策略,因為這些動作帶來最高的分數。這種自我學習的能力,讓 AI 不只是照表操課,而是有能力根據不同情況做出更聰明的選擇。
強化學習應用場景有哪些?遊戲對戰、自駕車、機器手臂
強化學習的應用場景非常多,尤其適合需要動作連續性和決策判斷的任務,最有名的例子就是 Google DeepMind 的 AlphaGo,它透過強化學習成功打敗世界棋王,震驚全球。
再來是自動駕駛車,AI 需要即時判斷路況、車速、行人動作,強化學習能幫助它學會最佳行駛策略。還有像機器手臂操作、倉儲搬運機器人等,都是透過試錯不斷優化動作流程,最終達成高效率又精準的控制。甚至在金融投資、能源管理等領域,也都有強化學習的實際應用。
關於AI人工智慧,你還可以參考:開發可切菜、摺衣服等單一功能機器手臂的Dyna Robotics,完成2,350萬美元的種子融資
AI機器學習|機器學習資料集的正確分法
在 AI 機器學習的世界裡,「資料」就是模型學習與進步的原料。就像廚師煮菜要有食材,AI 要變聰明也必須靠大量數據來訓練。然而,資料並不是「全部丟進去」就好,正確地分配與使用資料集,是決定模型成敗的關鍵。一個訓練效果再好的模型,如果在真實環境下表現失常,往往就是資料分配出了問題。
訓練集、驗證集、測試集的差異是什麼?
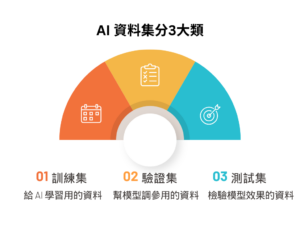
在實務上,AI 資料集會被分成三大類:
- 訓練集(Training Set):這是用來訓練模型的資料,AI 透過這些資料學習規則、找出特徵與模式,是整個模型建立的基礎。
- 驗證集(Validation Set):這一組資料不會拿去訓練,而是用來調整模型參數(例如:選擇最佳演算法、設定權重),確保模型在沒見過的資料上也能保持良好表現。
- 測試集(Test Set):最後的測試集是模型從頭到尾都沒看過的資料,用來模擬「實際使用時」模型的表現,檢驗準確度與泛化能力。
AI機器學習為什麼要分資料集防止過擬合?
AI 模型如果只在訓練資料上表現很好,但換一批資料表現卻慘不忍睹,就代表模型「過擬合(Overfitting)」了。這種狀況就像學生死背考古題,結果正式考試一題換掉就不會寫。
為了避免這種問題,我們必須透過驗證集與測試集,來觀察模型對於新資料的適應能力。只有模型在不同資料集上都有穩定表現,才能說是真正學會「舉一反三」,而不是死記硬背。
資料品質與分配比例會如何影響 AI 模型表現?
資料品質不佳(例如錯誤標記、重複樣本、資料偏差)會嚴重影響模型學習效果;即使是世界上最強的演算法,若餵進去的數據不準確,結果還是會失真。
同樣重要的還有分配比例,一般常見的切分方式是「訓練:驗證:測試 = 6:2:2 或 7:2:1」,但這比例並不是死規則,會依據資料量、模型複雜度與應用需求做調整。重點是資料必須多樣、均衡且具代表性,這樣模型才能學得準、測得準、預測得更準。
總結:打好基礎,才能真正學懂 AI 機器學習
不管你是剛踏入 AI 領域的新手,還是想補強觀念的實務者,理解 NLP、強化學習與資料集這三大核心觀念,都是學好 AI 機器學習的關鍵第一步。NLP 讓電腦能夠理解人類語言、強化學習教會 AI 用試錯找出最佳解,而資料集的正確分配與品質管理,更是模型準確度的根本。
只要打好基礎、搞懂邏輯,再複雜的 AI 技術也能迎刃而解。現在,就從理解這三個基本概念開始,為未來的 AI 學習之路奠定穩固的基石吧!
AI機器學習的5個常見問題
Q1:AI、機器學習、深度學習三者有什麼差別?
AI(人工智慧)是一個大範疇,包含所有讓機器模仿人類智慧的技術;機器學習(ML)是 AI 的一種,透過資料訓練讓電腦學會判斷;而深度學習(DL)是機器學習的進階應用,通常使用類似人腦神經網路的演算法,處理圖像、語音等複雜任務。
Q2:學 AI機器學習需要會寫程式嗎?
基本的程式能力是有幫助的,尤其是 Python 語言,因為多數機器學習框架(如 scikit-learn、TensorFlow、PyTorch)都以 Python 為主。不過現在也有許多低程式門檻的平台(如 DataRobot、Teachable Machine),讓初學者可以用圖形介面學習與操作 AI 模型。
Q3:資料集哪裡找?有免費的開放資源嗎?
有的,很多平台都提供免費開放資料集供學習與實驗使用,例如:Kaggle、UCI Machine Learning Repository、Google Dataset Search、台灣政府資料開放平台(data.gov.tw)等,這些資源都能幫助你快速開始模型訓練與測試。
Q4:AI模型準不準,是看準確率就夠了嗎?
不一定!準確率雖然重要,但還需搭配其他指標來看整體表現,例如:召回率(Recall)、精確率(Precision)、F1 分數,尤其在處理不平衡資料(如詐騙偵測)時,光看準確率可能會有誤導。評估模型好壞要看任務特性與整體表現。
Q5:學會機器學習後,可以做出什麼實際應用?
應用非常多!像是分類電子郵件、自動推薦商品、影像辨識、語音助手、醫療診斷預測、股價趨勢分析、客服聊天機器人等。AI機器學習的強項在於「用資料幫你做決策」,無論是企業分析還是個人專案,都能找到切入點。


